前一阵子中国新歌声举行了总决赛,最终,汪峰战队的蒋敦豪战胜周杰伦战队的向洋,夺得年度总冠。进入到第5个年头的《中国好声音》因版权纠纷更名为《中国新歌声》,首播全国网收视率2.24%,和去年相比有所下滑。而且“黑幕说”越演越烈,在鸟巢决赛夜的决赛投票环节81位评审竟然投出了92票,实在难以服众。

天谈这题目并不是立丰明年打算进军歌坛,主要想跟大家聊的是数据正确的重要性,一个不正确的数据对大家都会造成伤害。从新歌声的例子来看,首先,节目受到伤害,收视率下滑;其次,冠军受到伤害,大家觉得有黑幕;最后,观众受到伤害,谁希望被欺骗呢?从这简单的例子来看,我们数据工作者可谓责任重大,不可不谨慎。
最正确的数据,我们姑且称之为完美数据,我认为必须满足两个条件:全量、瞬间取得。全量很容易理解,为什么需要瞬间取得呢?想象一下,假如我需要了解:目前全北京有多少人喜欢吃烤鸭?于是我展开了一个全北京的普查,做了一年完成。这会碰到一个问题就是:这一年当中有些人从喜欢变不喜欢,有另一些人从不喜欢变喜欢;还有些人从北京人变成外地人,从外地人变北京人。所以即便你花了一年调查的全部的“北京人”,所得到的数据,仍然不能完美的说明:目前全北京有多少人喜欢吃烤鸭?所以,完美数据必须瞬间取得。谁有完美数据,我认为没有人拥有。我们能做的只是尽可能的接近它。
接下来我想利用两个维度来分类数据,并阐述我关于如何接近完美数据的看法。这两个维度就是:数据量与代表性。
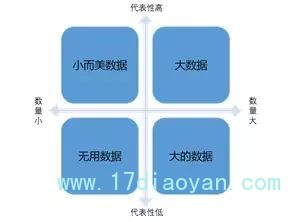
大数据
数量大且代表性高,最接近完美数据。如果你拥有大数据,那么恭喜你,你有很好的数据来做分析,得出的结果也会有很高的正确性。至于什么样的数据叫大数据,坊间有不少书籍介绍,我就不在这里赘述了。
大的数据
常与大数据混淆,让数据工作者误以为发现了珍宝。假设我要调查民众对做家务的态度,应该女生做还是男生做?如果我有三亿个样本量,听起来很令人兴奋吧,似乎我们就快发现真理了。但是,我告诉你,这三亿的样本量全是女性,你还会跟之前一样兴奋吗?当然不会,你知道这样的数据没有代表性。很多号称有大数据的公司,其实他们有的是大的数据。当我们面对大的数据的时候,冷静的去分析它的样本组成,清楚的说出它的有效范围,是我们数据工作者的专业与责任。
小而美的数据
为什么说它小而美呢?主要是这类的数据采集会经过严谨的抽样过程,针对我们研究对象的各个细分群体都有一定数量的样本。当然由于样本量小,得出的结论存在一定的抽样误差,没有办法有像大数据那样的正确性。但是,小而美数据有着时间短、成本低、弹性大的优势。多数时候也算是不错的数据来源。
无用数据
数量小又没有代表性,数据工作者处理这类数据时,必须清楚的说明这样的数据仅供参考,而且不要做过多的分析和解读,要不然会很容易误导读者。

谈了这四类的数据,最后回到我们的标题:大数据,信不信我“抽”你。如果是接近完美数据的大数据,那么当然就不“抽”(抽样)了。小数据肯定得狠狠的“抽”,这样才能成为小而美的数据。至于大的数据,那么就得在需要的地方“抽”一下了。数据量和代表性都是评判数据质量的关键要素,数据工作者在数据分析之前不可不思考。